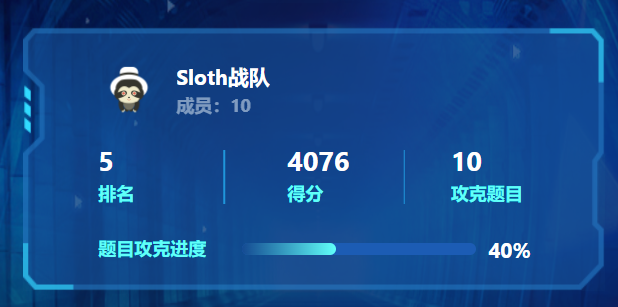
前天打完的TQLCTF,来总结一下自己独立输出的几个题(可能会有其他题的复现?咕咕咕了x
队友们tqltql!有被带飞到!
Reverse Tales of the Arrow 代码比较短,但是全是一堆randint
题目中并没有用到seed,同一份加密代码跑两遍出来的output.txt肯定也是不一样的,所以肯定不是随机数预测,所以就找漏洞(偏Crypto的思维了hhh
题目给的gen.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import randomprint("Enter the text within tqlctf{ ... }:" ) id = input ();id_bytes = bytes (id , "ascii" ) bits = '' .join(["{0:08b}" .format (x) for x in id_bytes]) n = len (bits) N = 5000 print(n) print(N) def get_lit (i ): return (i+1 ) * (2 *int (bits[i])-1 ) for t in range (N): i = random.randint(0 ,n-1 ) p = random.randint(0 ,2 ) true_lit = get_lit(i) for j in range (3 ): if j == p: print(true_lit) else : tmp = random.randint(0 ,n-1 ) rand_true = get_lit(tmp) if random.randint(0 ,3 )==0 : print(rand_true) else : print(-rand_true)
可以看到get_lit实际上就是返回一个数,get_lit(i)的返回值>0说明第i位是1,<0说明第i位是0,返回值一定为-(i+1)或i+1。
在主函数代码中,true_lit($\frac{1}{3}$概率)和rand_true($\frac{2}{3} \cdot \frac{1}{4}$概率)都会输出真实的get_lit,而-rand_true($\frac{2}{3} \cdot \frac{3}{4}$概率)输出的是相反的get_lit。
就是说只要输出-rand_true就说明在这一组(三个数一组)中j!=p,而每一组中必然有一个j==p和两个j!=p,所以只要这一组里有两个-rand_true那剩下的数一定就是true_lit。
理论有了,现在需要一个切入点。从id_bytes = bytes(id, "ascii")可以知道id为ASCII字符,并且通过input()输入大概率是可见的,那最高bit肯定是0(也就是每个字符的二进制必然是0???????),而这个就是切入点。
然后就能写出exp(while True里每一轮根据上一轮的已知结果来推,无脑循环;算法菜没优化,但速度出乎意料地快):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 with open ('output.txt' , 'r' ) as f: data = f.read().split('\n' ) n = int (data[0 ]) N = int (data[1 ]) data = list (map (int , data[2 :-1 ])) bits = ['_' for _ in range (n)] for i in range (n): if i % 8 == 0 : bits[i] = '0' while True : for i in range (0 , N * 3 , 3 ): neg = list ('+++' ) for j in range (3 ): if data[i+j] > 0 and bits[data[i+j]-1 ] == '0' : neg[j] = '-' elif data[i+j] < 0 and bits[-data[i+j]-1 ] == '1' : neg[j] = '-' if '' .join(neg).count('-' ) == 2 : idx = data[i+'' .join(neg).find('+' )] if idx < 0 : idx = -idx - 1 bits[idx] = '0' elif idx > 0 : idx -= 1 bits[idx] = '1' if '' .join(bits).find('_' ) == -1 : break flag = "" for i in range (0 , n, 8 ): flag += chr (int ('' .join(bits[i:i+8 ]), 2 )) print(flag)
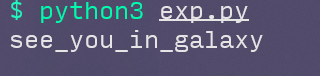
tqlctf{see_you_in_galaxy}
Misc the Ohio State University 下载附件看到是osz,音游人狂喜了属于是(
根据常识,出题人不可能为了出道题去写一张谱,所以跑去osu官网用歌名下到原谱面
然后对比了一下两个谱面文件的差异文件,可以看到题目中只有四个文件的修改时间是有变化的
所以从这四个文件下手,用010对比看修改了什么。
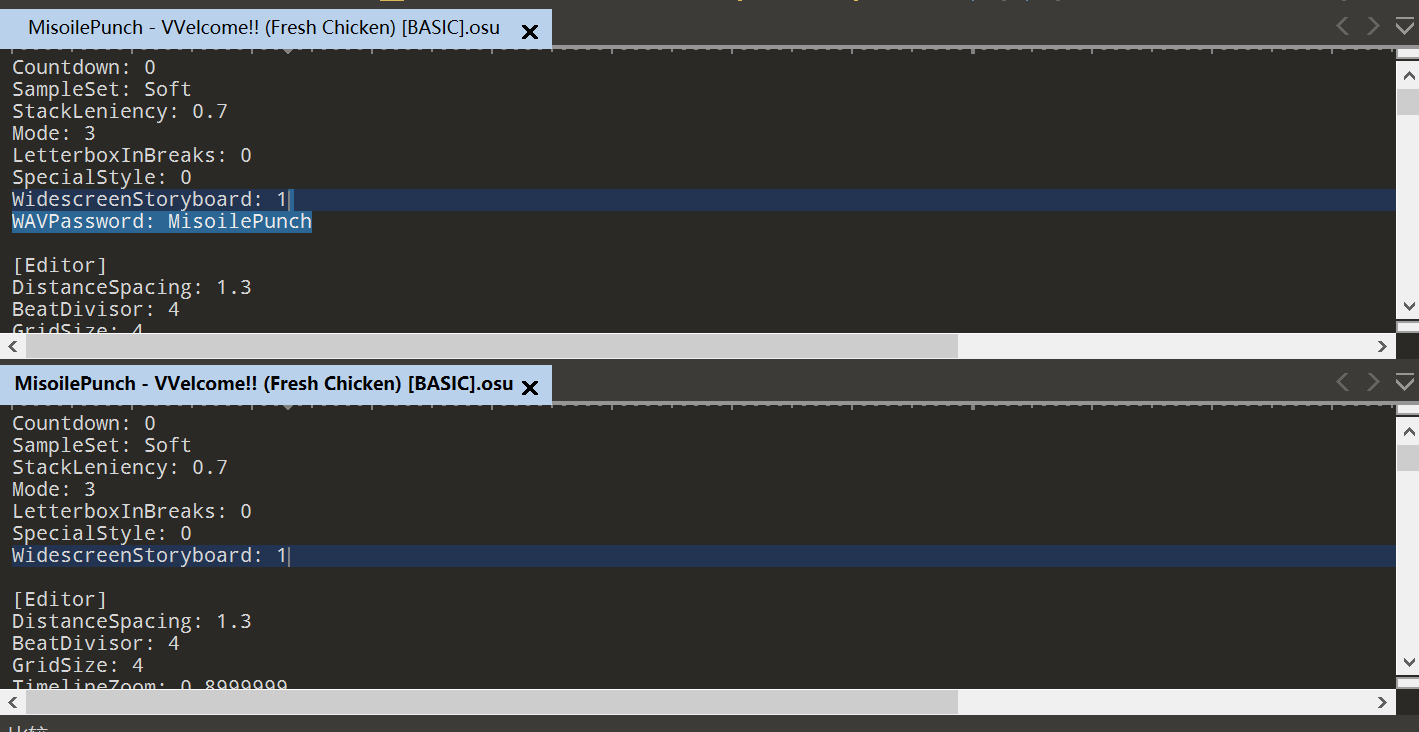
在BASIC谱面中多了一行WAVPassword: MisoilePunch,刚好有个boom.wav是被出题人改过的,所以猜测是用来解密这个wav的密码。
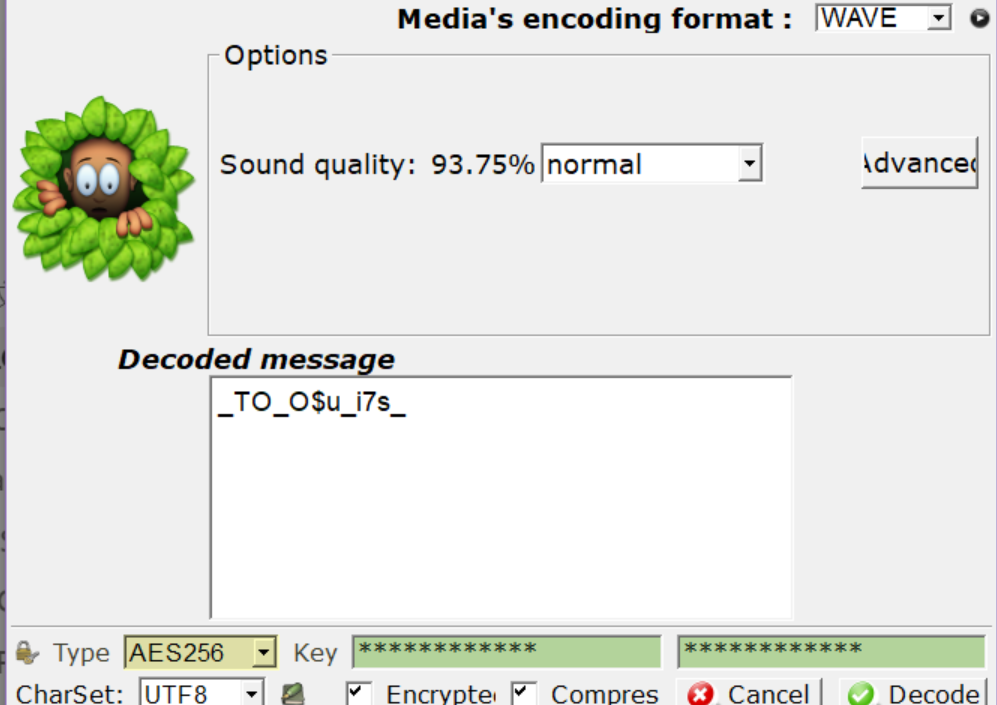
换了几个工具最后找到了SlientEye,解出flag的中间段:**_TO_O$u_i7s_**
然后VIVID是谱面有改动
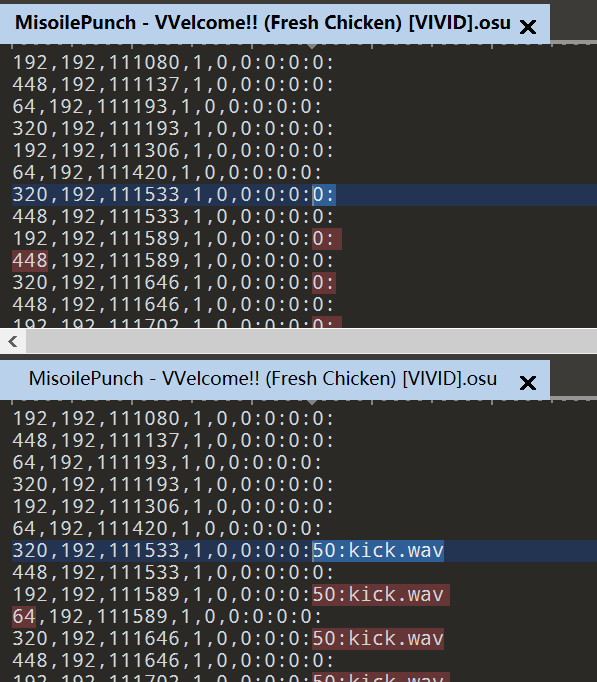
osu打开谱面编辑可以看到从111533时间戳开始,相同两行会重复四次,而两行四个位置加起来就是8,有note的位置为1没有note的位置为0就是一个字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import rewith open ('MisoilePunch - VVelcome!! (Fresh Chicken) [VIVID].osu' , 'r' ) as f: data = f.read().split('\n' ) idx_start = data.index('320,192,111533,1,0,0:0:0:0:' ) idx_end = data.index('448,192,115551,1,0,0:0:0:0:' ) data = data[idx_start:idx_end+1 ] notes = {} for i in range (len (data)): matchObj = re.search(r'(\d+),\d+,(\d+)' , data[i]) if matchObj.group(2 ) not in notes.keys(): notes.update({matchObj.group(2 ): [matchObj.group(1 )]}) else : notes[matchObj.group(2 )].append(matchObj.group(1 )) bits = '' pos = ['64' , '192' , '320' , '448' ] for x in notes.keys(): for y in pos: if y in notes[x]: bits += '1' else : bits += '0' print(bits) for i in range (0 , len (bits), 8 ): print(chr (int ('' .join(bits[i:i+8 ]), 2 )), end = '' )
可以得到flag的后半部分:**5HoWtIme}**
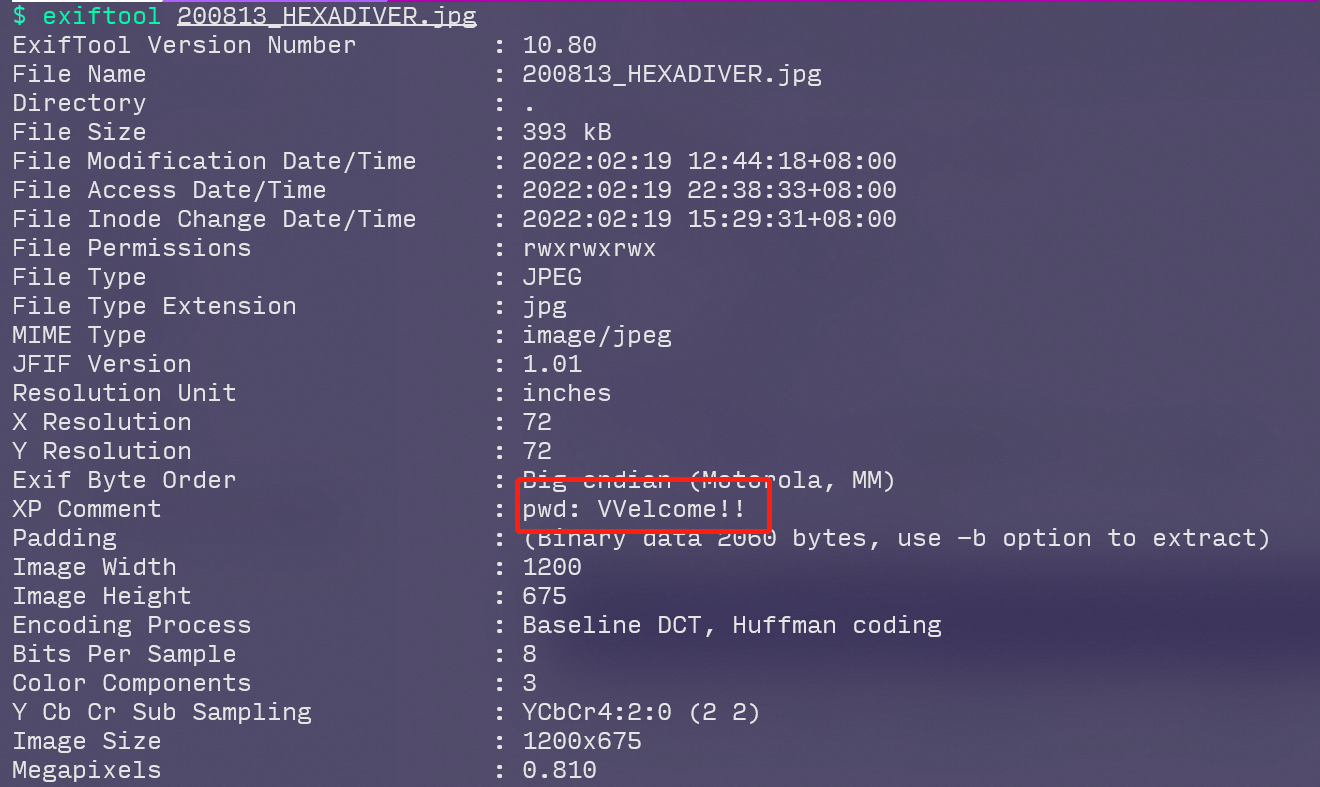
剩下不同的jpg文件应该是隐写了flag的最前部分,用exiftool可以看到有一个密码
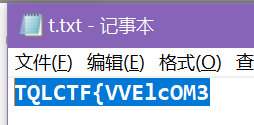
然后在这里 (CTF-图片隐写那些事儿 | Mssn Harvey ) 一个个工具试过来,用steghide可以解出flag的前半部分:**TQLCTF{VVElcOM3**
flag:TQLCTF{VVElcOM3_TO_O$u_i7s_5HoWtIme}
(学到了,之前想出osu的题但是懒得采音就作罢了,感谢出题人提供的全新思路)
Ranma½ 看起来符合utf8的编码逻辑,找到一篇现成代码Unicode和UTF-8关系及UTF-8编码规则及过滤Emoji表情 ,把里面的java代码抄了一份python版出来,exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 with open ('flag_4c7b25b7ade73ac3a6b3081c81633fe6' , 'rb' ) as f: data = f.read() i = 0 s = '' while i < len (data): code = 0 if (data[i] & 0x80 ) == 0x0 : code = data[i] i += 1 elif (data[i] & 0xE0 ) == 0xC0 : code = ((data[i] & 0x1F ) << 6 ) | (data[i+1 ] & 0x3F ) i += 2 elif (data[i] & 0xF0 ) == 0xE0 : code = (((data[i] & 0x0F )) << 12 ) | ((data[i + 1 ] & 0x3F ) << 6 ) | (data[i + 2 ] & 0x3F ) i += 3 elif (data[i] & 0xF8 ) == 0xF0 : code = ((t1[i] & 0x07 ) << 18 ) | ((t1[i + 1 ] & 0x3F ) << 12 ) | ((t1[i + 2 ] & 0x3F ) << 6 ) | (t1[i + 3 ] & 0x3F ) i += 4 if code != 0 : s += chr (code) print(s)
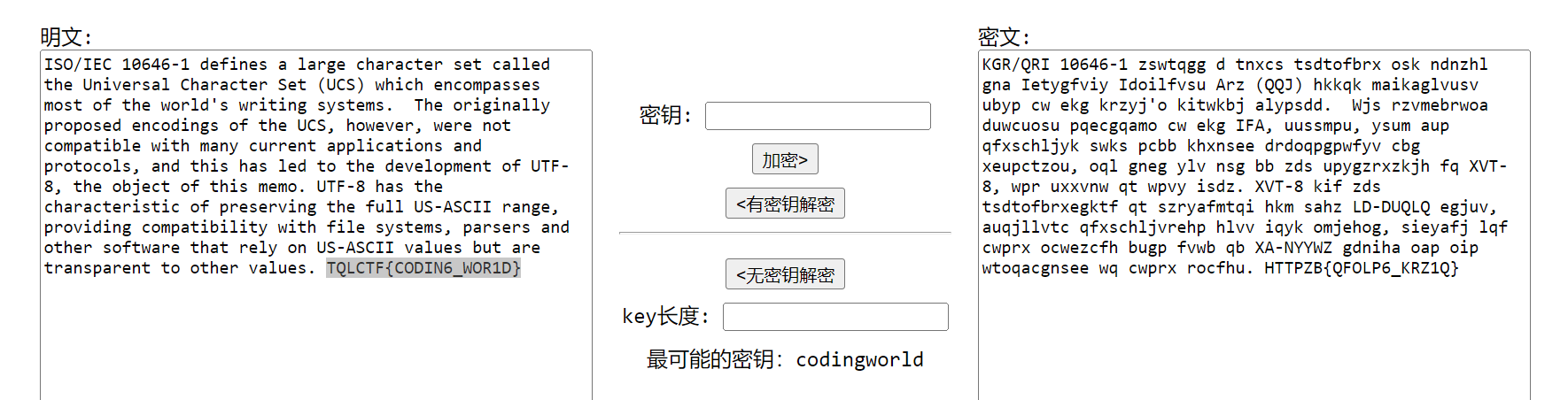
可以看到末尾有个HTTPZB和大括号,猜测这里原来应该是TQLCTF{},原文两个T连一块那可以排除凯撒和简单一对一替换了,于是掏出陈年法宝来猜密钥未知的Vigenere
https://atomcated.github.io/Vigenere/
然后可以看到flag:TQLCTF{CODIN6_WOR1D}
(所以跟日本那个同名漫画有什么关系呢,还看了好半天的wiki
Cat&Soup 是复现! 出题人wp在:TQLCTF Official Writeup By Nano | Non-existent World ,感谢出题人Nano师傅给这个研究不太懂wp的菜鸡(指指自己)提供了一些思路点拨和脚本参考_(:з」∠)_
首先题目下载下来拿到的是一个加密压缩包,本来以为需要爆破弱密码,后来队友@CSOME 发现压缩包数据里有完整的png头和尾,完全可以把图片提取出来。
提取脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def get_png (alldata ): idx_start = alldata.index(b'\x89\x50\x4E\x47' ) idx_end = alldata.index(b'\xAE\x42\x60\x82' ) return idx_start, idx_end + 4 with open ('Cat&Soup.zip' , 'rb' ) as f: data = f.read() with open ('cat.png' , 'wb' ) as f: start, end = get_png(data) f.write(data[start:end]) data = data[end:] with open ('soup.png' , 'wb' ) as f: start, end = get_png(data) f.write(data[start:end]) data = data[end:]
拿到两张图cat.png和soup.png,用exiftool、pngcheck等一堆工具都没看出有什么线索(果然这道题不是一道工具题呢x),用Stegsolve翻能翻到两张图片的某些颜色通道有很明显的水印。由题目的提示可以知道cat和soup的处理方式是不一样的,所以可以分开解析。
Cat 用Stegsolve可以看到在Red plane 0、Green plane 0、Blue plane 0都有这种点状水印。
把有水印的三个通道提取出来,可以写脚本也可以直接用Stegsolve的提取功能
分别保存成red.bmp、green.bmp、blue.bmp,然后对这几张图片分别进行cat变换即可,但是参数未知。(比赛的时候一直以为是逆变换,人傻了属于是x
我自己写的cat变换部分代码,暴力遍历每个像素确定新的位置:
1 2 3 4 5 for i in range (width): for j in range (height): new_i = (i + a*j) % width new_j = (j + b*new_i) % height res_img[new_j, new_i] = img[j, i]
但是爆破参数的时候发现这个代码出奇的慢,爆破大范围的时候实在是接受不了,所以仿出题人给的脚本改了一下:(我也不知道为什么这样比较快,难道numpy库内部加了一些特殊处理来加速吗)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from PIL import Imageimport numpy as npdef arnold (im_file, a, b ): img = np.array(Image.open (im_file)) height, width, color = img.shape res_img = np.zeros((height, width, color), dtype=int ) step = 0 for j in range (height): if step == 0 : res_img[j] = img[j] else : res_img[j, :step] = img[j, -step:] res_img[j, step:] = img[j, :-step] step = (step+a) % width img = res_img res_img = np.zeros((height, width, color), dtype=int ) step = 0 for i in range (width): if step == 0 : res_img[:, i] = img[:, i] else : res_img[:step, i] = img[-step:, i] res_img[step:, i] = img[:-step, i] step = (step+b) % height Image.fromarray(np.uint8(res_img)).save('output_{}/res_a{}_b{}.png' .format (im_file[:im_file.index('.' )], a, b))
爆破参数从横向变换的参数a开始爆破,纵向变换参数b设成0。这里以爆破red通道参数为例。
1 2 3 for tmpa in range (500 ): arnold('red.bmp' , tmpa, 0 )
范围不一定是500哈,没看到合适的得接着往后爆
爆破完以后可以在output_red文件夹(当然这个文件夹需要事先创建)中看到非——常多让人眼花缭乱的图。
一张张翻过去(亲身经历五百张很快的,看到不对翻过去就得了)。
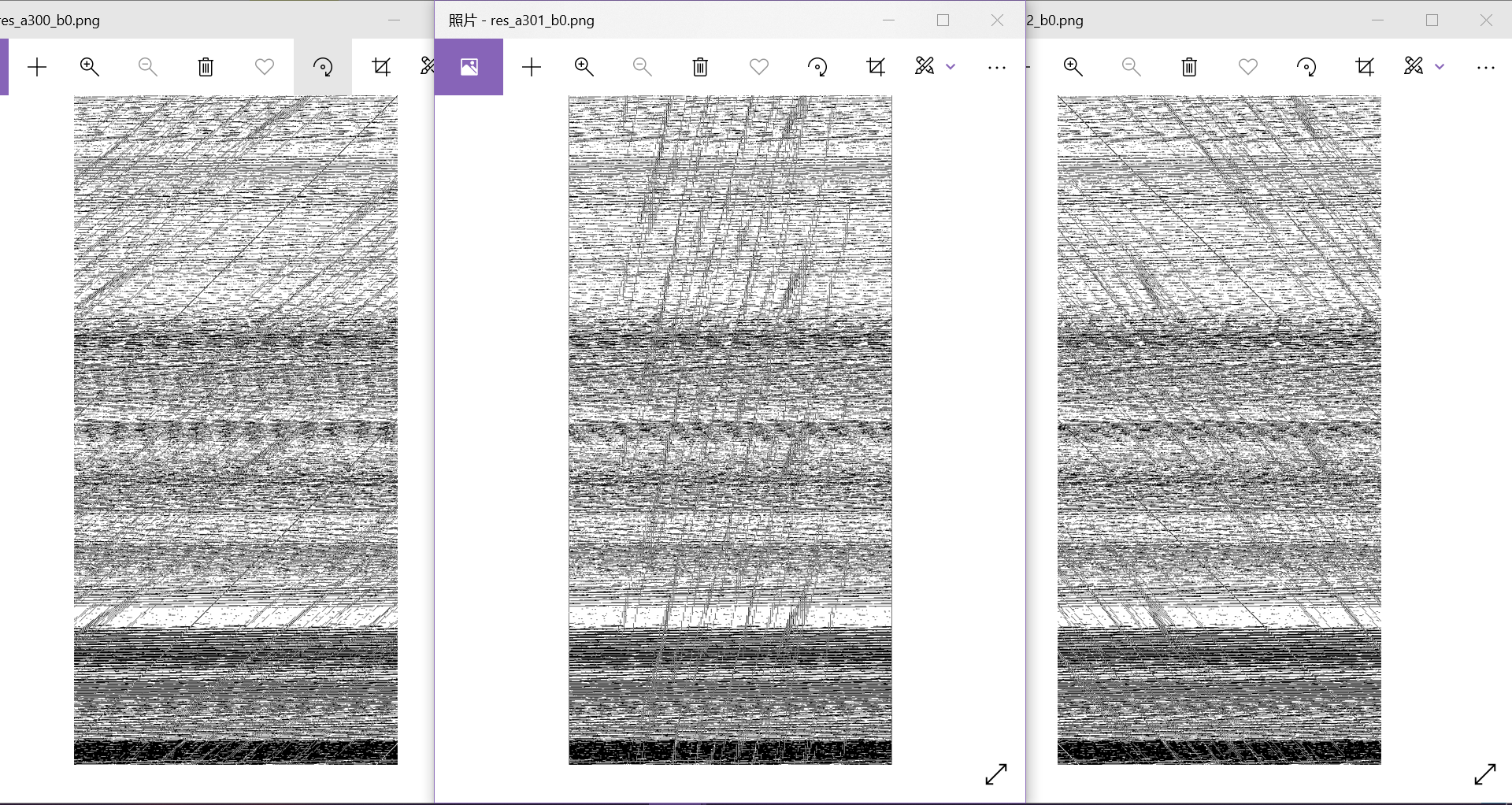
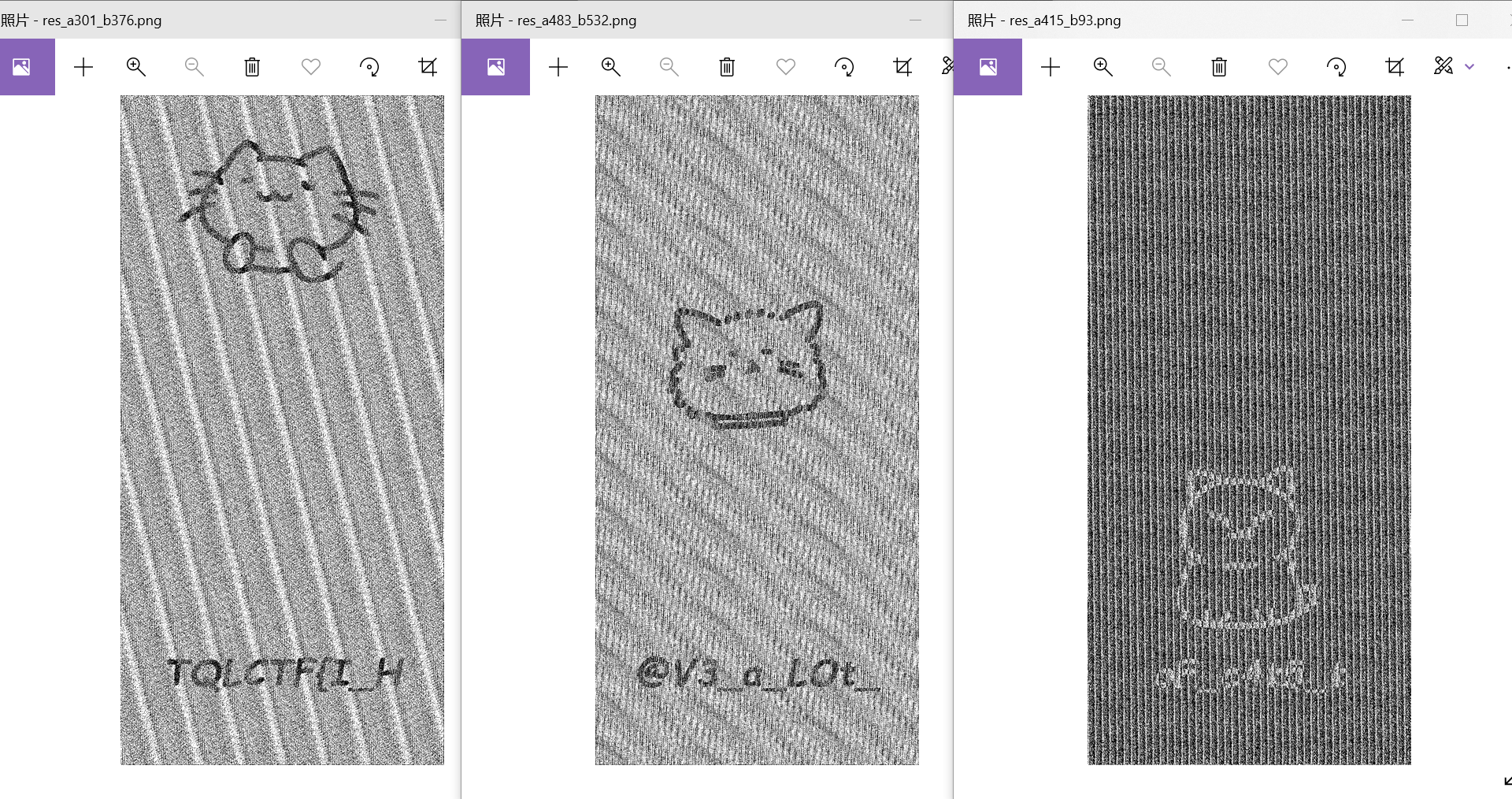
看到三张连续的这样的图说明参数找到了
300有很明显的斜率k=1的斜线、301有明显的线条(在前面图案里没见过的)、302是斜率k=-1的斜线,在300-302之间有一个从上升变到下降的过程,说明a很有可能就是中间的301,就是出题人wp里说的爆破方法:
爆出a=301以后,接着爆破b,就能看到很明显的有flag的图片(其实不用染色也挺明显的
拿到了红色通道隐藏的开头部分flag。
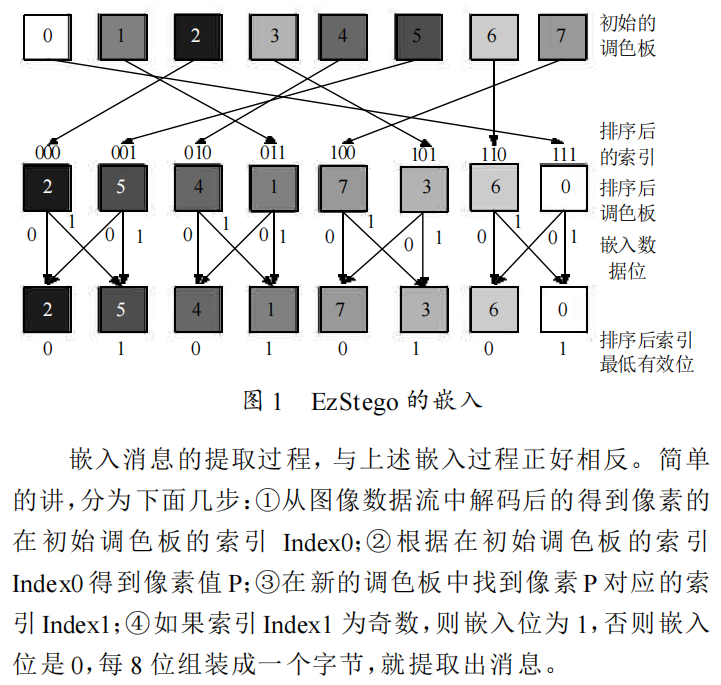
绿色通道爆破a的图像:
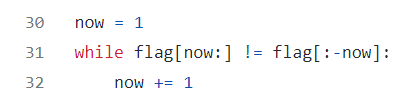
蓝色通道爆破a的图像:
最后拿到了三只小猫的图像(爆破a参数看到眼要瞎了哈哈哈哈,b参数的爆破倒是没有难度)
想知道参数的朋友直接看上图↑文件名就可)
前半段flag:TQLCTF{I_H@V3_a_LOt_oF_c4t5_t
Soup 感觉题目第一个提示说的”和soup有关“应该是来源于npy@Tover 找的这篇论文:Waiter! There’s a Message in My Soup ,里面同样提到了提示2说的调色板隐写算法。
调色板隐写算法的描述:(来自文章《EzStego的嵌入、提取与检测的C++实现》 )
然后就是按着写脚本啦,本题是7位组成一个字节(看到隐写数据里1打头就要警觉了),然后把flag隐写了无数次直到图片末尾。
出题人wp里用了一个很巧妙的方法来检查循环的数据串(学到了+1
(如果是我的话估计会把所有都print出来然后人眼看)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from PIL import Imageimport numpy as npimg = Image.open ('soup.png' ) width, height = img.size palette = img.getpalette() palette = [palette[i:i+3 ] for i in range (0 , len (palette), 3 )] luminance = [0.299 * t[0 ] + 0.587 * t[1 ] + 0.114 * t[2 ] for t in palette] idx0 = np.argsort(luminance) idx1 = [0 ] * 256 for i in range (len (idx0)): idx1[idx0[i]] = i data = '' for i in range (width): for j in range (height): x = img.getpixel((i, j)) data += str (idx1[x] % 2 ) now = 1 while data[now:] != data[:-now]: now += 1 flag = '' for i in range (0 , now, 7 ): tmp = data[i:i+7 ] flag += chr (int (tmp, 2 )) print(flag)
拿到后半段flag:HeR3_4R3_$oooOo0_CU7e!}
拼起来就能拿到整个flag:TQLCTF{I_H@V3_a_LOt_oF_c4t5_tHeR3_4R3_$oooOo0_CU7e!}
最后前线第一报道:某个Tover在比赛第二天的时候为了截图看跟题目的区别,把游戏下下来玩了,结果越玩越上瘾 ,甚至无心工作(
”这游戏有什么好玩的啊“
(然后真香